2024
|
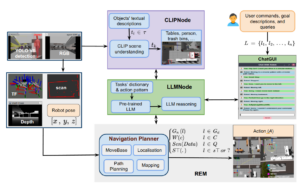
Nwankwo, Linus; Rueckert, Elmar The Conversation is the Command: Interacting with Real-World Autonomous Robot Through Natural Language Proceedings Article In: ACM/IEEE International Conference on Human-Robot Interaction (HRI ’24 Companion)., IEEE 2024, (Published as late breaking results. Supplementary video: https://cloud.cps.unileoben.ac.at/index.php/s/fRE9XMosWDtJ339 ). @inproceedings{Nwankwo2024,
title = {The Conversation is the Command: Interacting with Real-World Autonomous Robot Through Natural Language},
author = {Linus Nwankwo and Elmar Rueckert},
url = {https://cloud.cps.unileoben.ac.at/index.php/s/YzJdHWDt9ZdqsZs},
year = {2024},
date = {2024-01-16},
urldate = {2024-01-16},
booktitle = {ACM/IEEE International Conference on Human-Robot Interaction (HRI ’24 Companion).},
organization = {IEEE},
howpublished = {ACM/IEEE International Conference on Human-Robot Interaction (HRI ’24 Companion)},
note = {Published as late breaking results. Supplementary video: https://cloud.cps.unileoben.ac.at/index.php/s/fRE9XMosWDtJ339 },
keywords = {Autonomous Navigation, Large Language Models},
pubstate = {published},
tppubtype = {inproceedings}
}
|  |
2023
|
Yadav, Harsh; Xue, Honghu; Rudall, Yan; Bakr, Mohamed; Hein, Benedikt; Rueckert, Elmar; Nguyen, Ngoc Thinh Deep Reinforcement Learning for Mapless Navigation of Autonomous Mobile Robot Proceedings Article In: International Conference on System Theory, Control and Computing (ICSTCC), 2023, (October 11-13, 2023, Timisoara, Romania.). @inproceedings{Yadav2023b,
title = {Deep Reinforcement Learning for Mapless Navigation of Autonomous Mobile Robot},
author = {Harsh Yadav and Honghu Xue and Yan Rudall and Mohamed Bakr and Benedikt Hein and Elmar Rueckert and Ngoc Thinh Nguyen},
url = {https://cloud.cps.unileoben.ac.at/index.php/s/zEnY3yoFHZRdzkR},
year = {2023},
date = {2023-06-26},
urldate = {2023-06-26},
publisher = { International Conference on System Theory, Control and Computing (ICSTCC)},
note = {October 11-13, 2023, Timisoara, Romania.},
keywords = {Autonomous Navigation, Deep Learning, Reinforcement Learning},
pubstate = {published},
tppubtype = {inproceedings}
}
|  |
2022
|
Xue, Honghu; Song, Rui; Petzold, Julian; Hein, Benedikt; Hamann, Heiko; Rueckert, Elmar End-To-End Deep Reinforcement Learning for First-Person Pedestrian Visual Navigation in Urban Environments Proceedings Article In: International Conference on Humanoid Robots (Humanoids 2022), 2022. @inproceedings{Xue2022b,
title = {End-To-End Deep Reinforcement Learning for First-Person Pedestrian Visual Navigation in Urban Environments},
author = {Honghu Xue and Rui Song and Julian Petzold and Benedikt Hein and Heiko Hamann and Elmar Rueckert},
url = {https://cloud.cps.unileoben.ac.at/index.php/s/RzMQWqsFarQ6Kw4},
year = {2022},
date = {2022-09-26},
urldate = {2022-09-26},
publisher = {International Conference on Humanoid Robots (Humanoids 2022)},
abstract = {We solve a visual navigation problem in an urban setting via deep reinforcement learning in an end-to-end manner. A major challenge of a first-person visual navigation problem lies in severe partial observability and sparse positive experiences of reaching the goal. To address partial observability, we propose a novel 3D-temporal convolutional network to encode sequential historical visual observations, its effectiveness is verified by comparing to a commonly-used frame-stacking
approach. For sparse positive samples, we propose an improved automatic curriculum learning algorithm NavACL+, which
proposes meaningful curricula starting from easy tasks and gradually generalizes to challenging ones. NavACL+ is shown to
facilitate the learning process, greatly improve the task success rate on difficult tasks by at least 40% and offer enhanced
generalization to different initial poses compared to training from a fixed initial pose and the original NavACL algorithm.},
keywords = {Autonomous Navigation, Deep Learning, mobile navigation},
pubstate = {published},
tppubtype = {inproceedings}
}
We solve a visual navigation problem in an urban setting via deep reinforcement learning in an end-to-end manner. A major challenge of a first-person visual navigation problem lies in severe partial observability and sparse positive experiences of reaching the goal. To address partial observability, we propose a novel 3D-temporal convolutional network to encode sequential historical visual observations, its effectiveness is verified by comparing to a commonly-used frame-stacking
approach. For sparse positive samples, we propose an improved automatic curriculum learning algorithm NavACL+, which
proposes meaningful curricula starting from easy tasks and gradually generalizes to challenging ones. NavACL+ is shown to
facilitate the learning process, greatly improve the task success rate on difficult tasks by at least 40% and offer enhanced
generalization to different initial poses compared to training from a fixed initial pose and the original NavACL algorithm. |  |

