2024
|
Feith, Nikolaus; Rueckert, Elmar Advancing Interactive Robot Learning: A User Interface Leveraging Mixed Reality and Dual Quaternions Proceedings Article In: IEEE International Conference on Ubiquitous Robots (UR 2024), IEEE 2024. @inproceedings{Feith2024B,
title = {Advancing Interactive Robot Learning: A User Interface Leveraging Mixed Reality and Dual Quaternions},
author = {Nikolaus Feith and Elmar Rueckert},
url = {https://cloud.cps.unileoben.ac.at/index.php/s/qCgzbmCJYSH3F97},
year = {2024},
date = {2024-04-04},
urldate = {2024-04-04},
booktitle = {IEEE International Conference on Ubiquitous Robots (UR 2024)},
organization = {IEEE},
keywords = {Human-Robot Interaction, Mixted Reality, Robot Learning},
pubstate = {published},
tppubtype = {inproceedings}
}
|  |
Nwankwo, Linus; Rueckert, Elmar Multimodal Human-Autonomous Agents Interaction Using Pre-Trained Language and Visual Foundation Models Conference In Workshop of the 2024 ACM/IEEE International Conference on HumanRobot Interaction (HRI ’24 Workshop), March 11–14, 2024, Boulder, CO, USA.
ACM, New York, NY, USA, 2024. @conference{Nwankwo2024MultimodalHA,
title = {Multimodal Human-Autonomous Agents Interaction Using Pre-Trained Language and Visual Foundation Models},
author = {Linus Nwankwo and Elmar Rueckert},
url = {https://human-llm-interaction.github.io/workshop/hri24/papers/hllmi24_paper_5.pdf},
year = {2024},
date = {2024-03-11},
urldate = {2024-03-11},
booktitle = { In Workshop of the 2024 ACM/IEEE International Conference on HumanRobot Interaction (HRI ’24 Workshop), March 11–14, 2024, Boulder, CO, USA.
ACM, New York, NY, USA},
abstract = {In this paper, we extended the method proposed in [17] to enable humans to interact naturally with autonomous agents through vocal and textual conversations. Our extended method exploits the inherent capabilities of pre-trained large language models (LLMs), multimodal visual language models (VLMs), and speech recognition (SR) models to decode the high-level natural language conversations and semantic understanding of the robot's task environment, and abstract them to the robot's actionable commands or queries. We performed a quantitative evaluation of our framework's natural vocal conversation understanding with participants from different racial backgrounds and English language accents. The participants interacted with the robot using both vocal and textual instructional commands. Based on the logged interaction data, our framework achieved 87.55% vocal commands decoding accuracy, 86.27% commands execution success, and an average latency of 0.89 seconds from receiving the participants' vocal chat commands to initiating the robot’s actual physical action. The video demonstrations of this paper can be found at https://linusnep.github.io/MTCC-IRoNL/},
keywords = {Autonomous Navigation, Human-Robot Interaction, Large Language Models, mobile navigation},
pubstate = {published},
tppubtype = {conference}
}
In this paper, we extended the method proposed in [17] to enable humans to interact naturally with autonomous agents through vocal and textual conversations. Our extended method exploits the inherent capabilities of pre-trained large language models (LLMs), multimodal visual language models (VLMs), and speech recognition (SR) models to decode the high-level natural language conversations and semantic understanding of the robot's task environment, and abstract them to the robot's actionable commands or queries. We performed a quantitative evaluation of our framework's natural vocal conversation understanding with participants from different racial backgrounds and English language accents. The participants interacted with the robot using both vocal and textual instructional commands. Based on the logged interaction data, our framework achieved 87.55% vocal commands decoding accuracy, 86.27% commands execution success, and an average latency of 0.89 seconds from receiving the participants' vocal chat commands to initiating the robot’s actual physical action. The video demonstrations of this paper can be found at https://linusnep.github.io/MTCC-IRoNL/ | 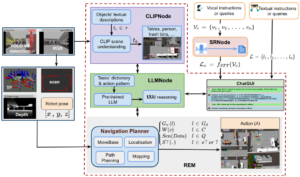 |