

Publication List with Images
2025 |
|
Dave, Vedant; Rueckert, Elmar Skill Disentanglement in Reproducing Kernel Hilbert Space Proceedings Article In: Proceedings of the AAAI Conference on Artificial Intelligence (AAAI), pp. 16153-16162, 2025. Abstract | Links | BibTeX | Tags: Deep Learning, neural network, Reinforcement Learning, Skill Discovery, Unsupervised Learning @inproceedings{Dave2025bb,Unsupervised Skill Discovery aims at learning diverse skills without any extrinsic rewards and leverage them as prior for learning a variety of downstream tasks. Existing approaches to unsupervised reinforcement learning typically involve discovering skills through empowerment-driven techniques or by maximizing entropy to encourage exploration. However, this mutual information objective often results in either static skills that discourage exploration or maximise coverage at the expense of non-discriminable skills. Instead of focusing only on maximizing bounds on f-divergence, we combine it with Integral Probability Metrics to maximize the distance between distributions to promote behavioural diversity and enforce disentanglement. Our method, Hilbert Unsupervised Skill Discovery (HUSD), provides an additional objective that seeks to obtain exploration and separability of state-skill pairs by maximizing the Maximum Mean Discrepancy between the joint distribution of skills and states and the product of their marginals in Reproducing Kernel Hilbert Space. Our results on Unsupervised RL Benchmark show that HUSD outperforms previous exploration algorithms on state-based tasks. |  |
Oezdenizci, Ozan; Rueckert, Elmar; Legenstein, Robert Privacy-Aware Lifelong Learning Proceedings Article In: International Conference on Learning Representations (ICLR), 2025. Links | BibTeX | Tags: Deep Learning, machine learning @inproceedings{Oezdenizci2025, | 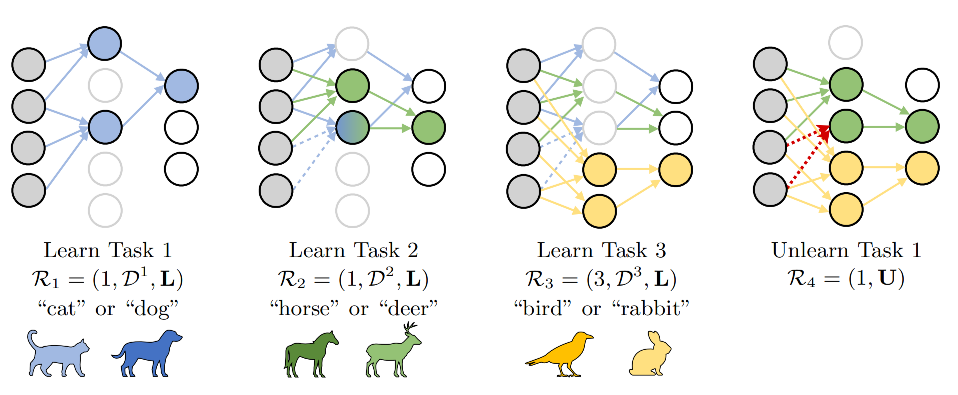 |
2024 |
|
Neubauer, Melanie; Rueckert, Elmar Semi-Autonomous Fast Object Segmentation and Tracking Tool for Industrial Applications Proceedings Article In: IEEE International Conference on Ubiquitous Robots (UR 2024), IEEE 2024. Links | BibTeX | Tags: computer vision, Deep Learning, Recycling @inproceedings{neubauer2024fost, | 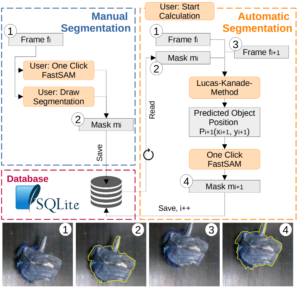 |
2023 |
|
Yadav, Harsh; Xue, Honghu; Rudall, Yan; Bakr, Mohamed; Hein, Benedikt; Rueckert, Elmar; Nguyen, Ngoc Thinh Deep Reinforcement Learning for Mapless Navigation of Autonomous Mobile Robot Proceedings Article In: International Conference on System Theory, Control and Computing (ICSTCC), 2023, (October 11-13, 2023, Timisoara, Romania.). Links | BibTeX | Tags: Autonomous Navigation, Deep Learning, Reinforcement Learning @inproceedings{Yadav2023b, |  |
2022 |
|
Xue, Honghu; Song, Rui; Petzold, Julian; Hein, Benedikt; Hamann, Heiko; Rueckert, Elmar End-To-End Deep Reinforcement Learning for First-Person Pedestrian Visual Navigation in Urban Environments Proceedings Article In: International Conference on Humanoid Robots (Humanoids 2022), 2022. Abstract | Links | BibTeX | Tags: Autonomous Navigation, Deep Learning, mobile navigation @inproceedings{Xue2022b,We solve a visual navigation problem in an urban setting via deep reinforcement learning in an end-to-end manner. A major challenge of a first-person visual navigation problem lies in severe partial observability and sparse positive experiences of reaching the goal. To address partial observability, we propose a novel 3D-temporal convolutional network to encode sequential historical visual observations, its effectiveness is verified by comparing to a commonly-used frame-stacking approach. For sparse positive samples, we propose an improved automatic curriculum learning algorithm NavACL+, which proposes meaningful curricula starting from easy tasks and gradually generalizes to challenging ones. NavACL+ is shown to facilitate the learning process, greatly improve the task success rate on difficult tasks by at least 40% and offer enhanced generalization to different initial poses compared to training from a fixed initial pose and the original NavACL algorithm. |  |
2020 |
|
Akbulut, M Tuluhan; Oztop, Erhan; Seker, M Yunus; Xue, Honghu; Tekden, Ahmet E; Ugur, Emre ACNMP: Skill Transfer and Task Extrapolation through Learning from Demonstration and Reinforcement Learning via Representation Sharing Proceedings Article In: 2020. Abstract | Links | BibTeX | Tags: Deep Learning, movement primitives, Transfer Learning @inproceedings{nokey,To equip robots with dexterous skills, an effective approach is to first transfer the desired skill via Learning from Demonstration (LfD), then let the robot improve it by self-exploration via Reinforcement Learning (RL). In this paper, we propose a novel LfD+RL framework, namely Adaptive Conditional Neural Movement Primitives (ACNMP), that allows efficient policy improvement in novel environments and effective skill transfer between different agents. This is achieved through exploiting the latent representation learned by the underlying Conditional Neural Process (CNP) model, and simultaneous training of the model with supervised learning (SL) for acquiring the demonstrated trajectories and via RL for new trajectory discovery. Through simulation experiments, we show that (i) ACNMP enables the system to extrapolate to situations where pure LfD fails; (ii) Simultaneous training of the system through SL and RL preserves the shape of demonstrations while adapting to novel situations due to the shared representations used by both learners; (iii) ACNMP enables order-of-magnitude sample-efficient RL in extrapolation of reaching tasks compared to the existing approaches; (iv) ACNMPs can be used to implement skill transfer between robots having different morphology, with competitive learning speeds and importantly with less number of assumptions compared to the state-of-the-art approaches. Finally, we show the real-world suitability of ACNMPs through real robot experiments that involve obstacle avoidance, pick and place and pouring actions. |  |
Compact List without Images
Proceedings Articles |
Dave, Vedant; Rueckert, Elmar Skill Disentanglement in Reproducing Kernel Hilbert Space Proceedings Article In: Proceedings of the AAAI Conference on Artificial Intelligence (AAAI), pp. 16153-16162, 2025. @inproceedings{Dave2025bb,Unsupervised Skill Discovery aims at learning diverse skills without any extrinsic rewards and leverage them as prior for learning a variety of downstream tasks. Existing approaches to unsupervised reinforcement learning typically involve discovering skills through empowerment-driven techniques or by maximizing entropy to encourage exploration. However, this mutual information objective often results in either static skills that discourage exploration or maximise coverage at the expense of non-discriminable skills. Instead of focusing only on maximizing bounds on f-divergence, we combine it with Integral Probability Metrics to maximize the distance between distributions to promote behavioural diversity and enforce disentanglement. Our method, Hilbert Unsupervised Skill Discovery (HUSD), provides an additional objective that seeks to obtain exploration and separability of state-skill pairs by maximizing the Maximum Mean Discrepancy between the joint distribution of skills and states and the product of their marginals in Reproducing Kernel Hilbert Space. Our results on Unsupervised RL Benchmark show that HUSD outperforms previous exploration algorithms on state-based tasks. |
Oezdenizci, Ozan; Rueckert, Elmar; Legenstein, Robert Privacy-Aware Lifelong Learning Proceedings Article In: International Conference on Learning Representations (ICLR), 2025. @inproceedings{Oezdenizci2025, |
Neubauer, Melanie; Rueckert, Elmar Semi-Autonomous Fast Object Segmentation and Tracking Tool for Industrial Applications Proceedings Article In: IEEE International Conference on Ubiquitous Robots (UR 2024), IEEE 2024. @inproceedings{neubauer2024fost, |
Yadav, Harsh; Xue, Honghu; Rudall, Yan; Bakr, Mohamed; Hein, Benedikt; Rueckert, Elmar; Nguyen, Ngoc Thinh Deep Reinforcement Learning for Mapless Navigation of Autonomous Mobile Robot Proceedings Article In: International Conference on System Theory, Control and Computing (ICSTCC), 2023, (October 11-13, 2023, Timisoara, Romania.). @inproceedings{Yadav2023b, |
Xue, Honghu; Song, Rui; Petzold, Julian; Hein, Benedikt; Hamann, Heiko; Rueckert, Elmar End-To-End Deep Reinforcement Learning for First-Person Pedestrian Visual Navigation in Urban Environments Proceedings Article In: International Conference on Humanoid Robots (Humanoids 2022), 2022. @inproceedings{Xue2022b,We solve a visual navigation problem in an urban setting via deep reinforcement learning in an end-to-end manner. A major challenge of a first-person visual navigation problem lies in severe partial observability and sparse positive experiences of reaching the goal. To address partial observability, we propose a novel 3D-temporal convolutional network to encode sequential historical visual observations, its effectiveness is verified by comparing to a commonly-used frame-stacking approach. For sparse positive samples, we propose an improved automatic curriculum learning algorithm NavACL+, which proposes meaningful curricula starting from easy tasks and gradually generalizes to challenging ones. NavACL+ is shown to facilitate the learning process, greatly improve the task success rate on difficult tasks by at least 40% and offer enhanced generalization to different initial poses compared to training from a fixed initial pose and the original NavACL algorithm. |
Akbulut, M Tuluhan; Oztop, Erhan; Seker, M Yunus; Xue, Honghu; Tekden, Ahmet E; Ugur, Emre ACNMP: Skill Transfer and Task Extrapolation through Learning from Demonstration and Reinforcement Learning via Representation Sharing Proceedings Article In: 2020. @inproceedings{nokey,To equip robots with dexterous skills, an effective approach is to first transfer the desired skill via Learning from Demonstration (LfD), then let the robot improve it by self-exploration via Reinforcement Learning (RL). In this paper, we propose a novel LfD+RL framework, namely Adaptive Conditional Neural Movement Primitives (ACNMP), that allows efficient policy improvement in novel environments and effective skill transfer between different agents. This is achieved through exploiting the latent representation learned by the underlying Conditional Neural Process (CNP) model, and simultaneous training of the model with supervised learning (SL) for acquiring the demonstrated trajectories and via RL for new trajectory discovery. Through simulation experiments, we show that (i) ACNMP enables the system to extrapolate to situations where pure LfD fails; (ii) Simultaneous training of the system through SL and RL preserves the shape of demonstrations while adapting to novel situations due to the shared representations used by both learners; (iii) ACNMP enables order-of-magnitude sample-efficient RL in extrapolation of reaching tasks compared to the existing approaches; (iv) ACNMPs can be used to implement skill transfer between robots having different morphology, with competitive learning speeds and importantly with less number of assumptions compared to the state-of-the-art approaches. Finally, we show the real-world suitability of ACNMPs through real robot experiments that involve obstacle avoidance, pick and place and pouring actions. |