

Publication List with Images
2025 |
|
Vanjani, Pankhuri; Mattes, Paul; Li, Maximilian Xiling; Dave, Vedant; Lioutikov, Rudolf DisDP: Robust Imitation Learning via Disentangled Diffusion Policies Proceedings Article In: Reinforcement Learning Conference (RLC), Reinforcement Learning Journal, 2025. Links | BibTeX | Tags: Contrastive Learning, Imitation Learning, Representation Learning @inproceedings{dave2025disdp, |  |
2024 |
|
Dave, Vedant; Rueckert, Elmar Denoised Predictive Imagination: An Information-theoretic approach for learning World Models Conference European Workshop on Reinforcement Learning (EWRL), 2024. Abstract | Links | BibTeX | Tags: computer vision, Contrastive Learning, Reinforcement Learning, Representation Learning @conference{dpidave2024,Humans excel at isolating relevant information from noisy data to predict the behavior of dynamic systems, effectively disregarding non-informative, temporally-correlated noise. In contrast, existing reinforcement learning algorithms face challenges in generating noise-free predictions within high-dimensional, noise-saturated environments, especially when trained on world models featuring realistic background noise extracted from natural video streams. We propose a novel information-theoretic approach that learn world models based on minimising the past information and retaining maximal information about the future, aiming at simultaneously learning control policies and at producing denoised predictions. Utilizing Soft Actor-Critic agents augmented with an information-theoretic auxiliary loss, we validate our method's effectiveness on complex variants of the standard DeepMind Control Suite tasks, where natural videos filled with intricate and task-irrelevant information serve as a background. Experimental results demonstrate that our model outperforms nine state-of-the-art approaches in various settings where natural videos serve as dynamic background noise. Our analysis also reveals that all these methods encounter challenges in more complex environments. |  |
Lygerakis, Fotios; Dave, Vedant; Rueckert, Elmar M2CURL: Sample-Efficient Multimodal Reinforcement Learning via Self-Supervised Representation Learning for Robotic Manipulation Proceedings Article In: IEEE International Conference on Ubiquitous Robots (UR 2024), IEEE 2024. Links | BibTeX | Tags: Contrastive Learning, Manipulation, Multimodal Reinforcement Learning, Multimodal Representation Learning, Reinforcement Learning, Robot Learning @inproceedings{Lygerakis2024, | 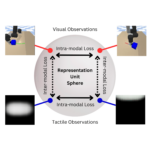 |
Dave*, Vedant; Lygerakis*, Fotios; Rueckert, Elmar Multimodal Visual-Tactile Representation Learning through Self-Supervised Contrastive Pre-Training Proceedings Article In: IEEE International Conference on Robotics and Automation (ICRA), pp. 8013-8020, IEEE, 2024, ISBN: 979-8-3503-8457-4, (* equal contribution). Abstract | Links | BibTeX | Tags: Contrastive Learning, Representation Learning, Self-supervised Learning, Tactile Sensing @inproceedings{Dave2024b,The rapidly evolving field of robotics necessitates methods that can facilitate the fusion of multiple modalities. Specifically, when it comes to interacting with tangible objects, effectively combining visual and tactile sensory data is key to understanding and navigating the complex dynamics of the physical world, enabling a more nuanced and adaptable response to changing environments. Nevertheless, much of the earlier work in merging these two sensory modalities has relied on supervised methods utilizing datasets labeled by humans. This paper introduces MViTac, a novel methodology that leverages contrastive learning to integrate vision and touch sensations in a self-supervised fashion. By availing both sensory inputs, MViTac leverages intra and inter-modality losses for learning representations, resulting in enhanced material property classification and more adept grasping prediction. Through a series of experiments, we showcase the effectiveness of our method and its superiority over existing state-of-the-art self-supervised and supervised techniques. In evaluating our methodology, we focus on two distinct tasks: material classification and grasping success prediction. Our results indicate that MViTac facilitates the development of improved modality encoders, yielding more robust representations as evidenced by linear probing assessments. https://sites.google.com/view/mvitac/home | 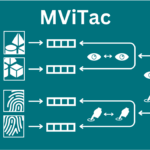 |
Compact List without Images
Conferences |
Dave, Vedant; Rueckert, Elmar Denoised Predictive Imagination: An Information-theoretic approach for learning World Models Conference European Workshop on Reinforcement Learning (EWRL), 2024. @conference{dpidave2024,Humans excel at isolating relevant information from noisy data to predict the behavior of dynamic systems, effectively disregarding non-informative, temporally-correlated noise. In contrast, existing reinforcement learning algorithms face challenges in generating noise-free predictions within high-dimensional, noise-saturated environments, especially when trained on world models featuring realistic background noise extracted from natural video streams. We propose a novel information-theoretic approach that learn world models based on minimising the past information and retaining maximal information about the future, aiming at simultaneously learning control policies and at producing denoised predictions. Utilizing Soft Actor-Critic agents augmented with an information-theoretic auxiliary loss, we validate our method's effectiveness on complex variants of the standard DeepMind Control Suite tasks, where natural videos filled with intricate and task-irrelevant information serve as a background. Experimental results demonstrate that our model outperforms nine state-of-the-art approaches in various settings where natural videos serve as dynamic background noise. Our analysis also reveals that all these methods encounter challenges in more complex environments. |
Proceedings Articles |
Vanjani, Pankhuri; Mattes, Paul; Li, Maximilian Xiling; Dave, Vedant; Lioutikov, Rudolf DisDP: Robust Imitation Learning via Disentangled Diffusion Policies Proceedings Article In: Reinforcement Learning Conference (RLC), Reinforcement Learning Journal, 2025. @inproceedings{dave2025disdp, |
Lygerakis, Fotios; Dave, Vedant; Rueckert, Elmar M2CURL: Sample-Efficient Multimodal Reinforcement Learning via Self-Supervised Representation Learning for Robotic Manipulation Proceedings Article In: IEEE International Conference on Ubiquitous Robots (UR 2024), IEEE 2024. @inproceedings{Lygerakis2024, |
Dave*, Vedant; Lygerakis*, Fotios; Rueckert, Elmar Multimodal Visual-Tactile Representation Learning through Self-Supervised Contrastive Pre-Training Proceedings Article In: IEEE International Conference on Robotics and Automation (ICRA), pp. 8013-8020, IEEE, 2024, ISBN: 979-8-3503-8457-4, (* equal contribution). @inproceedings{Dave2024b,The rapidly evolving field of robotics necessitates methods that can facilitate the fusion of multiple modalities. Specifically, when it comes to interacting with tangible objects, effectively combining visual and tactile sensory data is key to understanding and navigating the complex dynamics of the physical world, enabling a more nuanced and adaptable response to changing environments. Nevertheless, much of the earlier work in merging these two sensory modalities has relied on supervised methods utilizing datasets labeled by humans. This paper introduces MViTac, a novel methodology that leverages contrastive learning to integrate vision and touch sensations in a self-supervised fashion. By availing both sensory inputs, MViTac leverages intra and inter-modality losses for learning representations, resulting in enhanced material property classification and more adept grasping prediction. Through a series of experiments, we showcase the effectiveness of our method and its superiority over existing state-of-the-art self-supervised and supervised techniques. In evaluating our methodology, we focus on two distinct tasks: material classification and grasping success prediction. Our results indicate that MViTac facilitates the development of improved modality encoders, yielding more robust representations as evidenced by linear probing assessments. https://sites.google.com/view/mvitac/home |