2025
|
Keshavarz, Sahar; Elmgerbi, Asad; Dave, Vedant; Rückert, Elmar; Thonhauser, Gerhard Deep reinforcement learning for automated decision-making in wellbore construction Journal Article In: Energy Reports, vol. 14, pp. 3514-3528, 2025, ISSN: 2352-4847. @article{KESHAVARZ20253514,
title = {Deep reinforcement learning for automated decision-making in wellbore construction},
author = {Sahar Keshavarz and Asad Elmgerbi and Vedant Dave and Elmar Rückert and Gerhard Thonhauser},
url = {https://cloud.cps.unileoben.ac.at/index.php/s/X9wYbSpemJqrkW8},
doi = {https://doi.org/10.1016/j.egyr.2025.10.028},
issn = {2352-4847},
year = {2025},
date = {2025-11-02},
urldate = {2025-11-02},
journal = {Energy Reports},
volume = {14},
pages = {3514-3528},
abstract = {The drilling industry continuously seeks cost reduction through improved efficiency, with automation seen as a key solution. The drilling industry continuously seeks cost reduction through improved efficiency, with automation viewed as a key enabler. However, due to the complexity of drilling operations, uncertainty in subsurface conditions, and limitations in real-time data, achieving reliable autonomy remains a major challenge. While physics-based models support automation, they often face limitations under real-time constraints and may struggle to adapt effectively in the presence of uncertain or incomplete data. This study contributes to automation efforts by employing Reinforcement Learning (RL) to model hole conditioning, an essential part of drilling operation. Using a Q-learning approach, the RL agent optimizes operational decisions in real time, adapting based on environmental feedback. This artificial intelligence (AI) -driven agent identifies the ideal sequence of actions for circulation, reaming, and washing, maximizing operational safety and efficiency by aligning with target parameters while navigating operational constraints. The RL model decisions were benchmarked against real-case actions, demonstrating that the agent strategy can outperform expert choices in several areas. Specifically, the RL model provided better solutions in three key examples: avoiding poor hole cleaning, lowering the operational time, and preventing wellbore stability issues. The proposed system contributes to the growing body of research applying deep reinforcement learning for automated hole conditioning, representing an innovative engineering application for AI. This approach not only enhances real-time decision-making capabilities but also establishes a foundation for further automation in well construction, integrating engineering requirements with advanced AI-driven strategies. Through the combination of AI and practical engineering design, this work advances both automation and safety in drilling operations, signaling a promising step forward for future developments in wellbore construction.},
keywords = {Applied Deep Learning, Reinforcement Learning},
pubstate = {published},
tppubtype = {article}
}
The drilling industry continuously seeks cost reduction through improved efficiency, with automation seen as a key solution. The drilling industry continuously seeks cost reduction through improved efficiency, with automation viewed as a key enabler. However, due to the complexity of drilling operations, uncertainty in subsurface conditions, and limitations in real-time data, achieving reliable autonomy remains a major challenge. While physics-based models support automation, they often face limitations under real-time constraints and may struggle to adapt effectively in the presence of uncertain or incomplete data. This study contributes to automation efforts by employing Reinforcement Learning (RL) to model hole conditioning, an essential part of drilling operation. Using a Q-learning approach, the RL agent optimizes operational decisions in real time, adapting based on environmental feedback. This artificial intelligence (AI) -driven agent identifies the ideal sequence of actions for circulation, reaming, and washing, maximizing operational safety and efficiency by aligning with target parameters while navigating operational constraints. The RL model decisions were benchmarked against real-case actions, demonstrating that the agent strategy can outperform expert choices in several areas. Specifically, the RL model provided better solutions in three key examples: avoiding poor hole cleaning, lowering the operational time, and preventing wellbore stability issues. The proposed system contributes to the growing body of research applying deep reinforcement learning for automated hole conditioning, representing an innovative engineering application for AI. This approach not only enhances real-time decision-making capabilities but also establishes a foundation for further automation in well construction, integrating engineering requirements with advanced AI-driven strategies. Through the combination of AI and practical engineering design, this work advances both automation and safety in drilling operations, signaling a promising step forward for future developments in wellbore construction. | 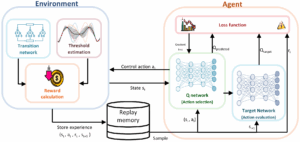 |
Dave, Vedant; Özdenizci, Ozan; Rückert, Elmar Learning Robust Representations for Visual Reinforcement Learning via Task-Relevant Mask Sampling Journal Article In: Transactions on Machine Learning Research, 2025. @article{dave2025learning,
title = {Learning Robust Representations for Visual Reinforcement Learning via Task-Relevant Mask Sampling},
author = {Vedant Dave and Ozan Özdenizci and Elmar Rückert},
url = {https://openreview.net/pdf?id=2rxNDxHwtn},
year = {2025},
date = {2025-09-18},
urldate = {2025-08-11},
journal = {Transactions on Machine Learning Research},
keywords = {machine learning, Reinforcement Learning, Representation Learning},
pubstate = {published},
tppubtype = {article}
}
|  |
Dave, Vedant; Rueckert, Elmar Skill Disentanglement in Reproducing Kernel Hilbert Space Proceedings Article In: Proceedings of the AAAI Conference on Artificial Intelligence (AAAI), pp. 16153-16162, 2025. @inproceedings{Dave2025bb,
title = {Skill Disentanglement in Reproducing Kernel Hilbert Space},
author = {Vedant Dave and Elmar Rueckert
},
url = {https://cloud.cps.unileoben.ac.at/index.php/s/m9XKo4t2FXAH6Cs},
doi = {https://doi.org/10.1609/aaai.v39i15.33774},
year = {2025},
date = {2025-04-11},
urldate = {2025-02-27},
booktitle = {Proceedings of the AAAI Conference on Artificial Intelligence (AAAI)},
volume = {39},
number = {15},
pages = {16153-16162},
abstract = {Unsupervised Skill Discovery aims at learning diverse skills without any extrinsic rewards and leverage them as prior for learning a variety of downstream tasks. Existing approaches to unsupervised reinforcement learning typically involve discovering skills through empowerment-driven techniques or by maximizing entropy to encourage exploration. However, this mutual information objective often results in either static skills that discourage exploration or maximise coverage at the expense of non-discriminable skills. Instead of focusing only on maximizing bounds on f-divergence, we combine it with Integral Probability Metrics to maximize the distance between distributions to promote behavioural diversity and enforce disentanglement. Our method, Hilbert Unsupervised Skill Discovery (HUSD), provides an additional objective that seeks to obtain exploration and separability of state-skill pairs by maximizing the Maximum Mean Discrepancy between the joint distribution of skills and states and the product of their marginals in Reproducing Kernel Hilbert Space. Our results on Unsupervised RL Benchmark show that HUSD outperforms previous exploration algorithms on state-based tasks.},
keywords = {Deep Learning, neural network, Reinforcement Learning, Skill Discovery, Unsupervised Learning},
pubstate = {published},
tppubtype = {inproceedings}
}
Unsupervised Skill Discovery aims at learning diverse skills without any extrinsic rewards and leverage them as prior for learning a variety of downstream tasks. Existing approaches to unsupervised reinforcement learning typically involve discovering skills through empowerment-driven techniques or by maximizing entropy to encourage exploration. However, this mutual information objective often results in either static skills that discourage exploration or maximise coverage at the expense of non-discriminable skills. Instead of focusing only on maximizing bounds on f-divergence, we combine it with Integral Probability Metrics to maximize the distance between distributions to promote behavioural diversity and enforce disentanglement. Our method, Hilbert Unsupervised Skill Discovery (HUSD), provides an additional objective that seeks to obtain exploration and separability of state-skill pairs by maximizing the Maximum Mean Discrepancy between the joint distribution of skills and states and the product of their marginals in Reproducing Kernel Hilbert Space. Our results on Unsupervised RL Benchmark show that HUSD outperforms previous exploration algorithms on state-based tasks. |  |
2024
|
Dave, Vedant; Rueckert, Elmar Denoised Predictive Imagination: An Information-theoretic approach for learning World Models Conference European Workshop on Reinforcement Learning (EWRL), 2024. @conference{dpidave2024,
title = {Denoised Predictive Imagination: An Information-theoretic approach for learning World Models},
author = {Vedant Dave and Elmar Rueckert},
url = {https://cps.unileoben.ac.at/wp/135_Denoised_Predictive_Imagin.pdf},
year = {2024},
date = {2024-08-01},
urldate = {2024-08-01},
publisher = {European Workshop on Reinforcement Learning (EWRL)},
abstract = {Humans excel at isolating relevant information from noisy data to predict the behavior of dynamic systems, effectively disregarding non-informative, temporally-correlated noise. In contrast, existing reinforcement learning algorithms face challenges in generating noise-free predictions within high-dimensional, noise-saturated environments, especially when trained on world models featuring realistic background noise extracted from natural video streams. We propose a novel information-theoretic approach that learn world models based on minimising the past information and retaining maximal information about the future, aiming at simultaneously learning control policies and at producing denoised predictions. Utilizing Soft Actor-Critic agents augmented with an information-theoretic auxiliary loss, we validate our method's effectiveness on complex variants of the standard DeepMind Control Suite tasks, where natural videos filled with intricate and task-irrelevant information serve as a background. Experimental results demonstrate that our model outperforms nine state-of-the-art approaches in various settings where natural videos serve as dynamic background noise. Our analysis also reveals that all these methods encounter challenges in more complex environments.},
keywords = {computer vision, Contrastive Learning, Reinforcement Learning, Representation Learning},
pubstate = {published},
tppubtype = {conference}
}
Humans excel at isolating relevant information from noisy data to predict the behavior of dynamic systems, effectively disregarding non-informative, temporally-correlated noise. In contrast, existing reinforcement learning algorithms face challenges in generating noise-free predictions within high-dimensional, noise-saturated environments, especially when trained on world models featuring realistic background noise extracted from natural video streams. We propose a novel information-theoretic approach that learn world models based on minimising the past information and retaining maximal information about the future, aiming at simultaneously learning control policies and at producing denoised predictions. Utilizing Soft Actor-Critic agents augmented with an information-theoretic auxiliary loss, we validate our method's effectiveness on complex variants of the standard DeepMind Control Suite tasks, where natural videos filled with intricate and task-irrelevant information serve as a background. Experimental results demonstrate that our model outperforms nine state-of-the-art approaches in various settings where natural videos serve as dynamic background noise. Our analysis also reveals that all these methods encounter challenges in more complex environments. |  |
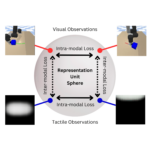
Lygerakis, Fotios; Dave, Vedant; Rueckert, Elmar M2CURL: Sample-Efficient Multimodal Reinforcement Learning via Self-Supervised Representation Learning for Robotic Manipulation Proceedings Article In: IEEE International Conference on Ubiquitous Robots (UR 2024), IEEE 2024. @inproceedings{Lygerakis2024,
title = {M2CURL: Sample-Efficient Multimodal Reinforcement Learning via Self-Supervised Representation Learning for Robotic Manipulation},
author = {Fotios Lygerakis and Vedant Dave and Elmar Rueckert},
url = {https://cloud.cps.unileoben.ac.at/index.php/s/NPejb2Fp4Y8LeyZ},
year = {2024},
date = {2024-04-04},
urldate = {2024-04-04},
booktitle = {IEEE International Conference on Ubiquitous Robots (UR 2024)},
organization = {IEEE},
keywords = {Contrastive Learning, Manipulation, Multimodal Reinforcement Learning, Multimodal Representation Learning, Reinforcement Learning, Robot Learning},
pubstate = {published},
tppubtype = {inproceedings}
}
|  |
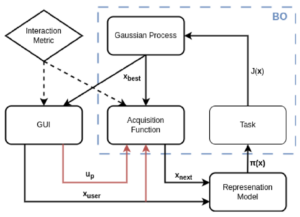
Feith, Nikolaus; Rueckert, Elmar Integrating Human Expertise in Continuous Spaces: A Novel Interactive Bayesian Optimization Framework with Preference Expected Improvement Proceedings Article In: IEEE International Conference on Ubiquitous Robots (UR 2024), IEEE 2024. @inproceedings{Feith2024A,
title = {Integrating Human Expertise in Continuous Spaces: A Novel Interactive Bayesian Optimization Framework with Preference Expected Improvement},
author = {Nikolaus Feith and Elmar Rueckert},
url = {https://cloud.cps.unileoben.ac.at/index.php/s/6rTWAkoXa3zsJxf},
year = {2024},
date = {2024-04-04},
urldate = {2024-04-04},
booktitle = {IEEE International Conference on Ubiquitous Robots (UR 2024)},
organization = {IEEE},
keywords = {Interactive Learning, Reinforcement Learning},
pubstate = {published},
tppubtype = {inproceedings}
}
|  |
2023
|
Yadav, Harsh; Xue, Honghu; Rudall, Yan; Bakr, Mohamed; Hein, Benedikt; Rueckert, Elmar; Nguyen, Ngoc Thinh Deep Reinforcement Learning for Mapless Navigation of Autonomous Mobile Robot Proceedings Article In: International Conference on System Theory, Control and Computing (ICSTCC), 2023, (October 11-13, 2023, Timisoara, Romania.). @inproceedings{Yadav2023b,
title = {Deep Reinforcement Learning for Mapless Navigation of Autonomous Mobile Robot},
author = {Harsh Yadav and Honghu Xue and Yan Rudall and Mohamed Bakr and Benedikt Hein and Elmar Rueckert and Ngoc Thinh Nguyen},
url = {https://cloud.cps.unileoben.ac.at/index.php/s/zEnY3yoFHZRdzkR},
year = {2023},
date = {2023-06-26},
urldate = {2023-06-26},
publisher = { International Conference on System Theory, Control and Computing (ICSTCC)},
note = {October 11-13, 2023, Timisoara, Romania.},
keywords = {Autonomous Navigation, Deep Learning, Reinforcement Learning},
pubstate = {published},
tppubtype = {inproceedings}
}
|  |
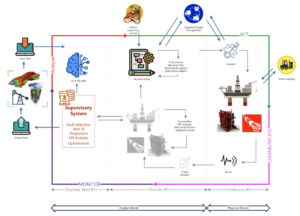
Keshavarz, Sahar; Vita, Petr; Rueckert, Elmar; Ortner, Ronald; Thonhauser, Gerhard A Reinforcement Learning Approach for Real-Time Autonomous Decision-Making in Well Construction Proceedings Article In: Society of Petroleum Engineers - SPE Symposium: Leveraging Artificial Intelligence to Shape the Future of the Energy Industry, AIS 2023, Society of Petroleum Engineers., 2023, ISBN: 9781613999882. @inproceedings{Keshavarz2023,
title = {A Reinforcement Learning Approach for Real-Time Autonomous Decision-Making in Well Construction},
author = {Sahar Keshavarz and Petr Vita and Elmar Rueckert and Ronald Ortner and Gerhard Thonhauser},
url = {https://cloud.cps.unileoben.ac.at/index.php/s/yT9Erwsnk36JKtr},
doi = {10.2118/214465-MS},
isbn = {9781613999882},
year = {2023},
date = {2023-01-19},
urldate = {2023-01-19},
booktitle = {Society of Petroleum Engineers - SPE Symposium: Leveraging Artificial Intelligence to Shape the Future of the Energy Industry, AIS 2023},
publisher = {Society of Petroleum Engineers.},
keywords = {Reinforcement Learning, Well Construction},
pubstate = {published},
tppubtype = {inproceedings}
}
|  |
2022
|
Xue, Honghu; Hein, Benedikt; Bakr, Mohamed; Schildbach, Georg; Abel, Bengt; Rueckert, Elmar Using Deep Reinforcement Learning with Automatic Curriculum Learning for Mapless Navigation in Intralogistics Journal Article In: Applied Sciences (MDPI), Special Issue on Intelligent Robotics, 2022, (Supplement: https://cloud.cps.unileoben.ac.at/index.php/s/Sj68rQewnkf4ppZ). @article{Xue2022,
title = {Using Deep Reinforcement Learning with Automatic Curriculum Learning for Mapless Navigation in Intralogistics},
author = {Honghu Xue and Benedikt Hein and Mohamed Bakr and Georg Schildbach and Bengt Abel and Elmar Rueckert},
editor = {/},
url = {https://cloud.cps.unileoben.ac.at/index.php/s/yddDZ7z9oqxenCi
},
year = {2022},
date = {2022-01-31},
urldate = {2022-01-31},
journal = {Applied Sciences (MDPI), Special Issue on Intelligent Robotics},
abstract = {We propose a deep reinforcement learning approach for solving a mapless navigation problem in warehouse scenarios. The automatic guided vehicle is equipped with LiDAR and frontal RGB sensors and learns to reach underneath the target dolly. The challenges reside in the sparseness of positive samples for learning, multi-modal sensor perception with partial observability, the demand for accurate steering maneuvers together with long training cycles. To address these points, we proposed NavACL-Q as an automatic curriculum learning together with distributed soft actor-critic. The performance of the learning algorithm is evaluated exhaustively in a different warehouse environment to check both robustness and generalizability of the learned policy. Results in NVIDIA Isaac Sim demonstrates that our trained agent significantly outperforms the map-based navigation pipeline provided by NVIDIA Isaac Sim in terms of higher agent-goal distances and relative orientations. The ablation studies also confirmed that NavACL-Q greatly facilitates the whole learning process and a pre-trained feature extractor manifestly boosts the training speed.},
note = {Supplement: https://cloud.cps.unileoben.ac.at/index.php/s/Sj68rQewnkf4ppZ},
keywords = {Autonomous Navigation, Deep Learning, mobile navigation, Reinforcement Learning},
pubstate = {published},
tppubtype = {article}
}
We propose a deep reinforcement learning approach for solving a mapless navigation problem in warehouse scenarios. The automatic guided vehicle is equipped with LiDAR and frontal RGB sensors and learns to reach underneath the target dolly. The challenges reside in the sparseness of positive samples for learning, multi-modal sensor perception with partial observability, the demand for accurate steering maneuvers together with long training cycles. To address these points, we proposed NavACL-Q as an automatic curriculum learning together with distributed soft actor-critic. The performance of the learning algorithm is evaluated exhaustively in a different warehouse environment to check both robustness and generalizability of the learned policy. Results in NVIDIA Isaac Sim demonstrates that our trained agent significantly outperforms the map-based navigation pipeline provided by NVIDIA Isaac Sim in terms of higher agent-goal distances and relative orientations. The ablation studies also confirmed that NavACL-Q greatly facilitates the whole learning process and a pre-trained feature extractor manifestly boosts the training speed. |  |
2021
|
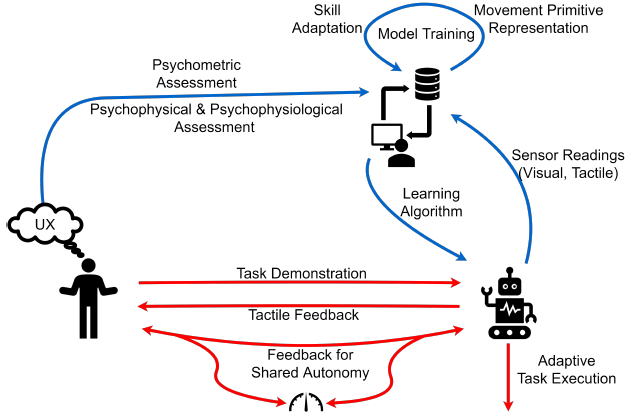
Cansev, Mehmet Ege; Xue, Honghu; Rottmann, Nils; Bliek, Adna; Miller, Luke E.; Rueckert, Elmar; Beckerle, Philipp Interactive Human-Robot Skill Transfer: A Review of Learning Methods and User Experience Journal Article In: Advanced Intelligent Systems, pp. 1–28, 2021. @article{Cansev2021,
title = {Interactive Human-Robot Skill Transfer: A Review of Learning Methods and User Experience},
author = {Mehmet Ege Cansev and Honghu Xue and Nils Rottmann and Adna Bliek and Luke E. Miller and Elmar Rueckert and Philipp Beckerle},
url = {https://cps.unileoben.ac.at/wp/AIS2021Cansev.pdf, Article File},
doi = {10.1002/aisy.202000247},
year = {2021},
date = {2021-03-10},
journal = {Advanced Intelligent Systems},
pages = {1--28},
keywords = {human motor control, intrinsic motivation, movement primitives, Probabilistic Inference, Reinforcement Learning, spiking},
pubstate = {published},
tppubtype = {article}
}
|  |
2020
|
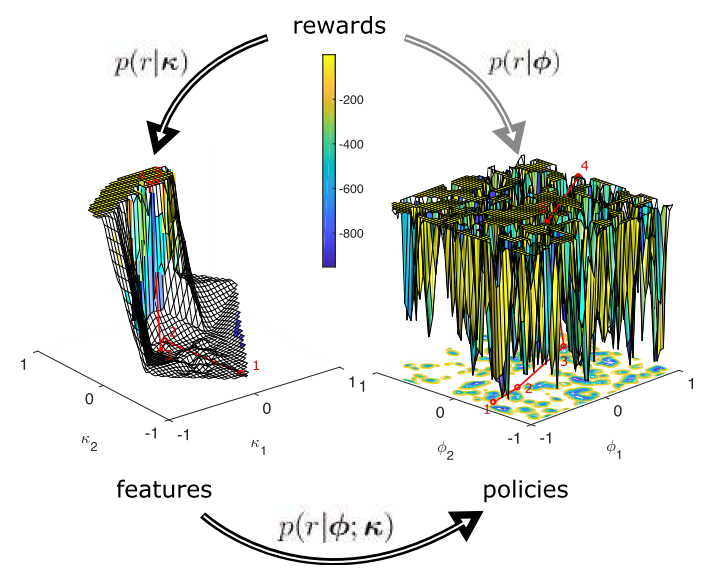
Rottmann, N.; Kunavar, T.; Babič, J.; Peters, J.; Rueckert, E. Learning Hierarchical Acquisition Functions for Bayesian Optimization Proceedings Article In: International Conference on Intelligent Robots and Systems (IROS’ 2020), 2020. @inproceedings{Rottmann2020HiBO,
title = {Learning Hierarchical Acquisition Functions for Bayesian Optimization},
author = {N. Rottmann and T. Kunavar and J. Babič and J. Peters and E. Rueckert},
url = {https://cps.unileoben.ac.at/wp/IROS2020Rottmann.pdf, Article File},
year = {2020},
date = {2020-10-25},
booktitle = {International Conference on Intelligent Robots and Systems (IROS’ 2020)},
keywords = {Reinforcement Learning},
pubstate = {published},
tppubtype = {inproceedings}
}
|  |
Rottmann, N.; Bruder, R.; Xue, H.; Schweikard, A.; Rueckert, E. Parameter Optimization for Loop Closure Detection in Closed Environments Conference Workshop Paper at the International Conference on Intelligent Robots and Systems (IROS), 2020. @conference{Rottmann2020c,
title = {Parameter Optimization for Loop Closure Detection in Closed Environments},
author = {N. Rottmann and R. Bruder and H. Xue and A. Schweikard and E. Rueckert},
url = {https://cps.unileoben.ac.at/wp/IROSWS2020Rottmann.pdf, Article File},
year = {2020},
date = {2020-10-25},
urldate = {2020-10-25},
booktitle = {Workshop Paper at the International Conference on Intelligent Robots and Systems (IROS)},
pages = {1--8},
keywords = {mobile navigation, Reinforcement Learning},
pubstate = {published},
tppubtype = {conference}
}
|  |
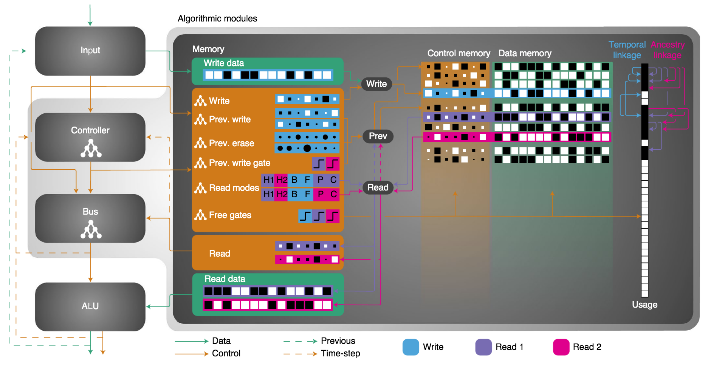
Tanneberg, Daniel; Rueckert, Elmar; Peters, Jan Evolutionary training and abstraction yields algorithmic generalization of neural computers Journal Article In: Nature Machine Intelligence, pp. 1–11, 2020. @article{Tanneberg2020,
title = {Evolutionary training and abstraction yields algorithmic generalization of neural computers},
author = {Daniel Tanneberg and Elmar Rueckert and Jan Peters },
url = {https://rdcu.be/caRlg, Article File},
doi = {10.1038/s42256-020-00255-1},
year = {2020},
date = {2020-10-10},
journal = {Nature Machine Intelligence},
pages = {1--11},
keywords = {neural network, Reinforcement Learning, Transfer Learning},
pubstate = {published},
tppubtype = {article}
}
|  |
Xue, H.; Boettger, S.; Rottmann, N.; Pandya, H.; Bruder, R.; Neumann, G.; Schweikard, A.; Rueckert, E. Sample-Efficient Covariance Matrix Adaptation Evolutional Strategy via Simulated Rollouts in Neural Networks Proceedings Article In: International Conference on Advances in Signal Processing and Artificial Intelligence (ASPAI’ 2020), 2020. @inproceedings{Xue2020,
title = {Sample-Efficient Covariance Matrix Adaptation Evolutional Strategy via Simulated Rollouts in Neural Networks},
author = {H. Xue and S. Boettger and N. Rottmann and H. Pandya and R. Bruder and G. Neumann and A. Schweikard and E. Rueckert},
url = {https://cps.unileoben.ac.at/wp/ASPAI2020Xue.pdf, Article File},
year = {2020},
date = {2020-06-30},
booktitle = {International Conference on Advances in Signal Processing and Artificial Intelligence (ASPAI’ 2020)},
keywords = {Manipulation, Reinforcement Learning},
pubstate = {published},
tppubtype = {inproceedings}
}
|  |
2019
|
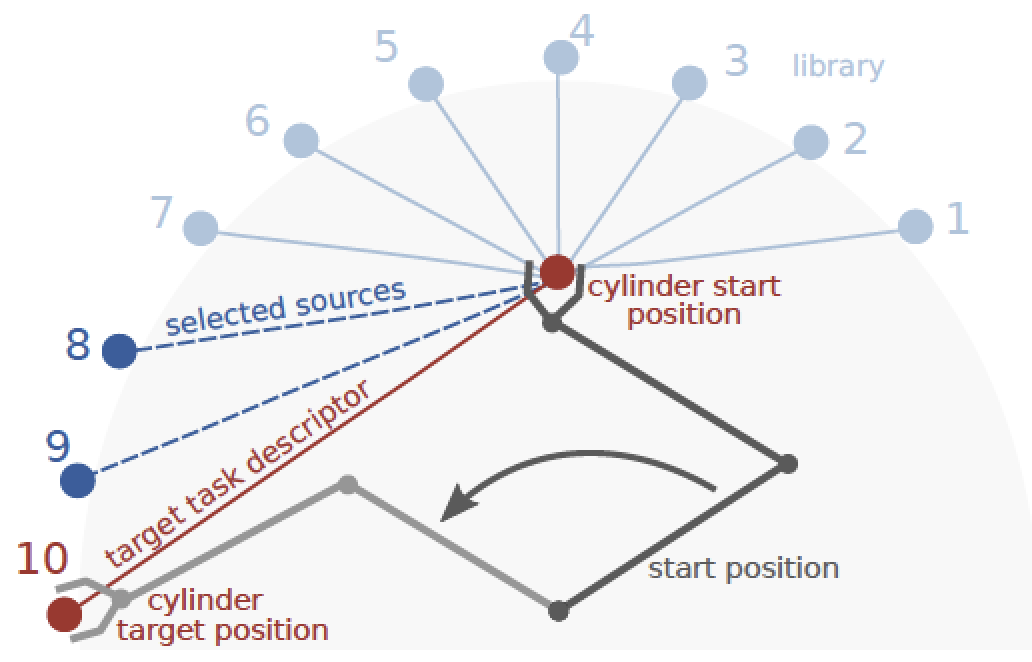
Stark, Svenja; Peters, Jan; Rueckert, Elmar Experience Reuse with Probabilistic Movement Primitives Proceedings Article In: Proceedings of the IEEE/RSJ Conference on Intelligent Robots and Systems (IROS), 2019., 2019. @inproceedings{Stark2019,
title = {Experience Reuse with Probabilistic Movement Primitives},
author = {Svenja Stark and Jan Peters and Elmar Rueckert},
url = {https://cps.unileoben.ac.at/wp/IROS2019Stark.pdf, Article File},
year = {2019},
date = {2019-11-03},
booktitle = {Proceedings of the IEEE/RSJ Conference on Intelligent Robots and Systems (IROS), 2019.},
keywords = {movement primitives, Reinforcement Learning, Transfer Learning},
pubstate = {published},
tppubtype = {inproceedings}
}
|  |
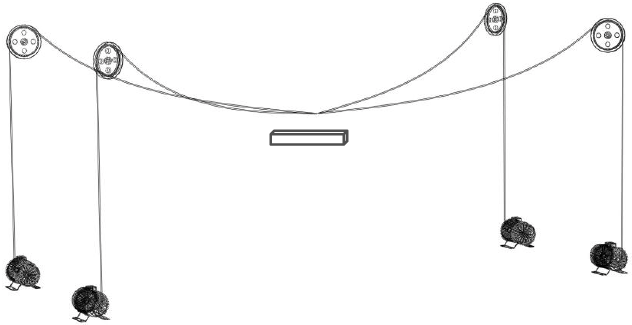
Rueckert, Elmar; Jauer, Philipp; Derksen, Alexander; Schweikard, Achim Dynamic Control Strategies for Cable-Driven Master Slave Robots Proceedings Article In: Keck, Tobias (Ed.): Proceedings on Minimally Invasive Surgery, Luebeck, Germany, 2019, (January 24-25, 2019). @inproceedings{Rueckert2019c,
title = {Dynamic Control Strategies for Cable-Driven Master Slave Robots},
author = {Elmar Rueckert and Philipp Jauer and Alexander Derksen and Achim Schweikard},
editor = {Tobias Keck},
doi = {10.18416/MIC.2019.1901007},
year = {2019},
date = {2019-01-24},
booktitle = {Proceedings on Minimally Invasive Surgery, Luebeck, Germany},
note = {January 24-25, 2019},
keywords = {Medical Robotics, Reinforcement Learning},
pubstate = {published},
tppubtype = {inproceedings}
}
|  |
2016
|
Sharma, David; Tanneberg, Daniel; Grosse-Wentrup, Moritz; Peters, Jan; Rueckert, Elmar Adaptive Training Strategies for BCIs Proceedings Article In: Cybathlon Symposium, 2016. @inproceedings{Sharma2016,
title = {Adaptive Training Strategies for BCIs},
author = {David Sharma and Daniel Tanneberg and Moritz Grosse-Wentrup and Jan Peters and Elmar Rueckert},
url = {https://cps.unileoben.ac.at/wp/Cybathlon2016Sharma.pdf, Article File},
year = {2016},
date = {2016-01-01},
booktitle = {Cybathlon Symposium},
crossref = {p10952},
keywords = {human motor control, Reinforcement Learning},
pubstate = {published},
tppubtype = {inproceedings}
}
|  |
2014
|
Rueckert, Elmar Biologically inspired motor skill learning in robotics through probabilistic inference PhD Thesis Technical University Graz, 2014. @phdthesis{Rueckert2014a,
title = {Biologically inspired motor skill learning in robotics through probabilistic inference},
author = {Elmar Rueckert},
url = {https://cps.unileoben.ac.at/wp/PhDThesis2014Rueckert.pdf, Article File},
year = {2014},
date = {2014-02-04},
school = {Technical University Graz},
keywords = {graphical models, locomotion, model learning, morphological compuation, movement primitives, policy search, postural control, Probabilistic Inference, Reinforcement Learning, RNN, SOC, spiking},
pubstate = {published},
tppubtype = {phdthesis}
}
|  |
2013
|
Rueckert, Elmar; d'Avella, Andrea Learned Muscle Synergies as Prior in Dynamical Systems for Controlling Bio-mechanical and Robotic Systems Proceedings Article In: Abstracts of Neural Control of Movement Conference (NCM), Conference Talk, pp. 27–28, 2013. @inproceedings{Rueckert2013,
title = {Learned Muscle Synergies as Prior in Dynamical Systems for Controlling Bio-mechanical and Robotic Systems},
author = {Elmar Rueckert and Andrea d'Avella},
url = {https://cps.unileoben.ac.at/wp/Frontiers2013bRueckert.pdf, Article File},
year = {2013},
date = {2013-01-01},
booktitle = {Abstracts of Neural Control of Movement Conference (NCM), Conference Talk},
pages = {27--28},
crossref = {p10682},
keywords = {muscle synergies, policy search, Reinforcement Learning},
pubstate = {published},
tppubtype = {inproceedings}
}
|  |